Clinical Informatics UMLS®
Summary
This repository contains a multi-step ETL process with a strong analytical and data science component for a deep dive into the Unified Medical Language System (UMLS®). The native .RRF files generated via MetamorphoSys will be loaded into a RDBMS-based datastore.
Data is transformed from the RDBMS to a Neo4j Label Property Graph with the target schema found in the next section of the README. If you are not familiar with Neo4j, you can check out all it has to offer at Neo4j.
Neo4j serves as the primary datastore for analysis of UMLS using Neo4j’s powerful tooling framework, including its native graph query language Cypher, in conjunction with three powerful Neo4j product/plugin offerings - APOC, Graph Data Science (GDS), and Neosemantics (N10s).
We use APOC and Graph Data Science (GDS) for powerful analytical approaches, which extend Neo4j’s unmatched ability to analyze, aggregate, and visualize rich interconnected data. As the world’s leading graph database, Neo4j provides industry-leading performance, flexibility, and versatility to analyze and make sense of such data. We use Neo4j’s product offering Neosemantics (N10s) to map the Neo4j LPG schema to a valid W3C RDF serialization and public schema, specifically schema.org.
If you are not familiar with Neo4j product/plugin offerings via Neo4j Labs, please check out the documentation for the following plugins:
Disclaimer
While this repository is open to anyone and has been created to share knowledge, educate, and contribute to the open source community, in order to access the source data from UMLS, you must be a UMLS® License Holder. Please visit How to License and Access the Unified Medical Language System® (UMLS®) Data to learn more. It is free, but requires a personal application and approval.
Note: All functionalities mentioned above currently
Neo4j Schema Representation of UMLS
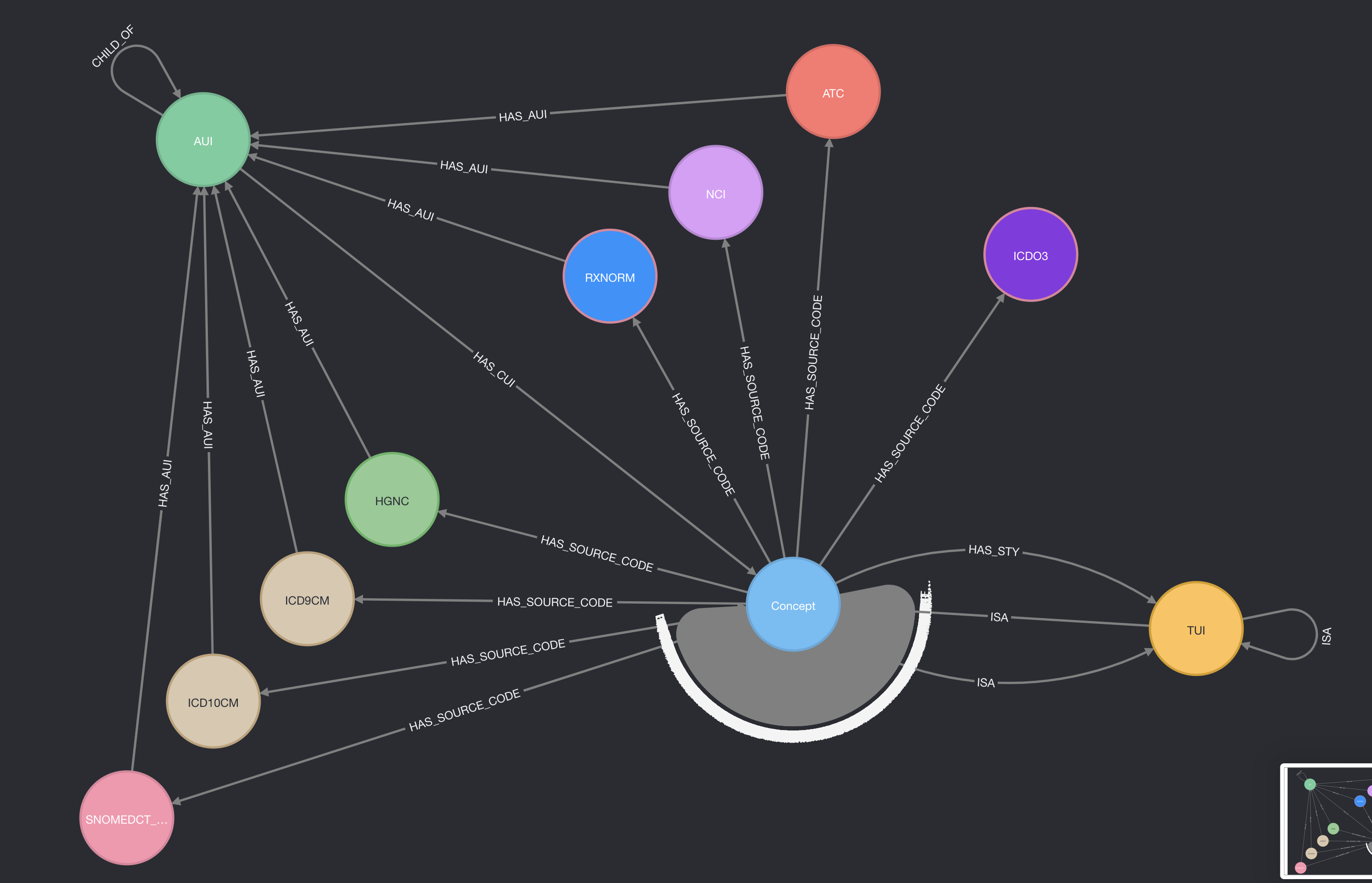
Schema Overview:
The schema shows the main elements (labels) of the graph that have been extracted from UMLS and transformed into a Neo4j Label Property Graph. These include:
- The UMLS atomic unique identifier (
UMLS.MRCONSO.AUI-Aui) - The UMLS concept unique identifier (
UMLS.MRCONSO.CUI-Cui) - The UMLS semantic unique identifier (
UMLS.MRCONSO.TUI-SemanticType) - The source vocabulary concept unique identifier (
UMLS.MRCONSO.CODE-Code)
The entire UMLS semantic network has been integrated into the graph via directed relationships to and from all semantic types within UMLS’s semantic network. The RDBMS to Neo4j transformation is achieved by running the python script clinical_informatics_umls/create_nodes_edges.py. This script can be configured to include or omit particular vocabularies and/or relationships.
The semantic network is related to the actual “concepts” contained in UMLS (i.e. Cui, Aui etc…) via the directed relationship HAS_STY. An example of how the semantic network relates to the actual “concepts” contained in the graph is provided in the Cypher query below:
MATCH path = (concept:CUI)-[:HAS_STY]->(semanticType:TUI)-[:ISA*]->(semanticTypeParent:TUI)
WHERE concept.CUI = "C2316164"
RETURN path
Another example of the semantic network is as follows:
The query illustrates the shortest path (amongst ISA relations only) between the descendant SemanticType - (TUI) -> Amino Acid, Peptide, or Protein and the “topConceptOf” OR “root” SemanticType - (TUI) -> Entity - (STY). See below:
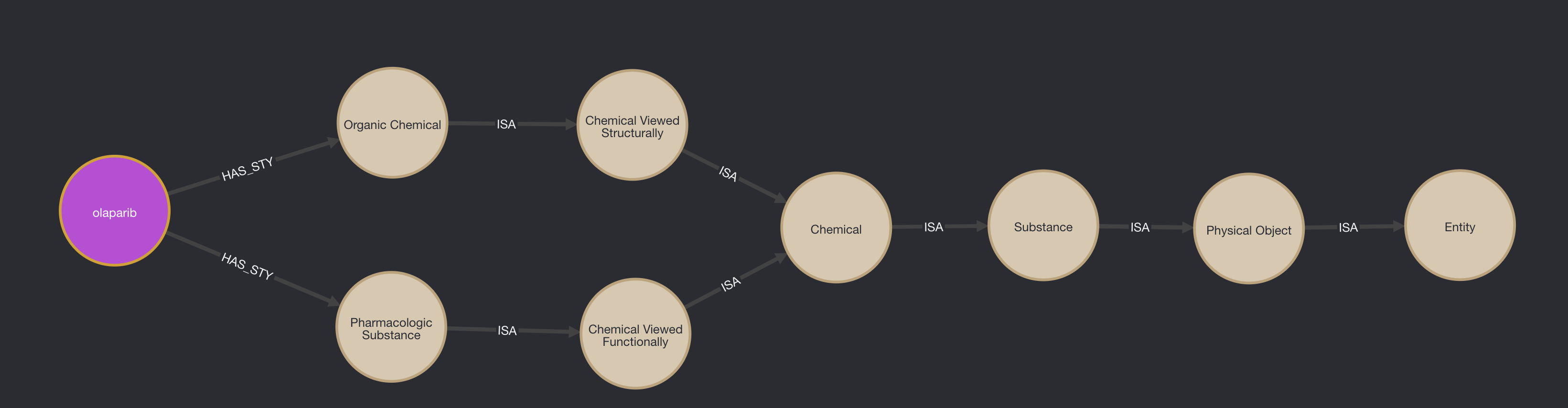
- The following is another example that illustrates how the semantic network constitutes its own linked graph structure as a stand-alone part of the entire graph.
- The query illustrates the shortest path between the descendant
SemanticType - (TUI)->Amino Acid, Peptide, or Proteinand the rootSemanticType - (TUI)->Entity - (STY). See below.
MATCH path = (to:TUI)<-[:ISA*]-(from:TUI)
WHERE to.STY = "Entity"
AND from.STY = "Amino Acid, Peptide, or Protein"
RETURN path
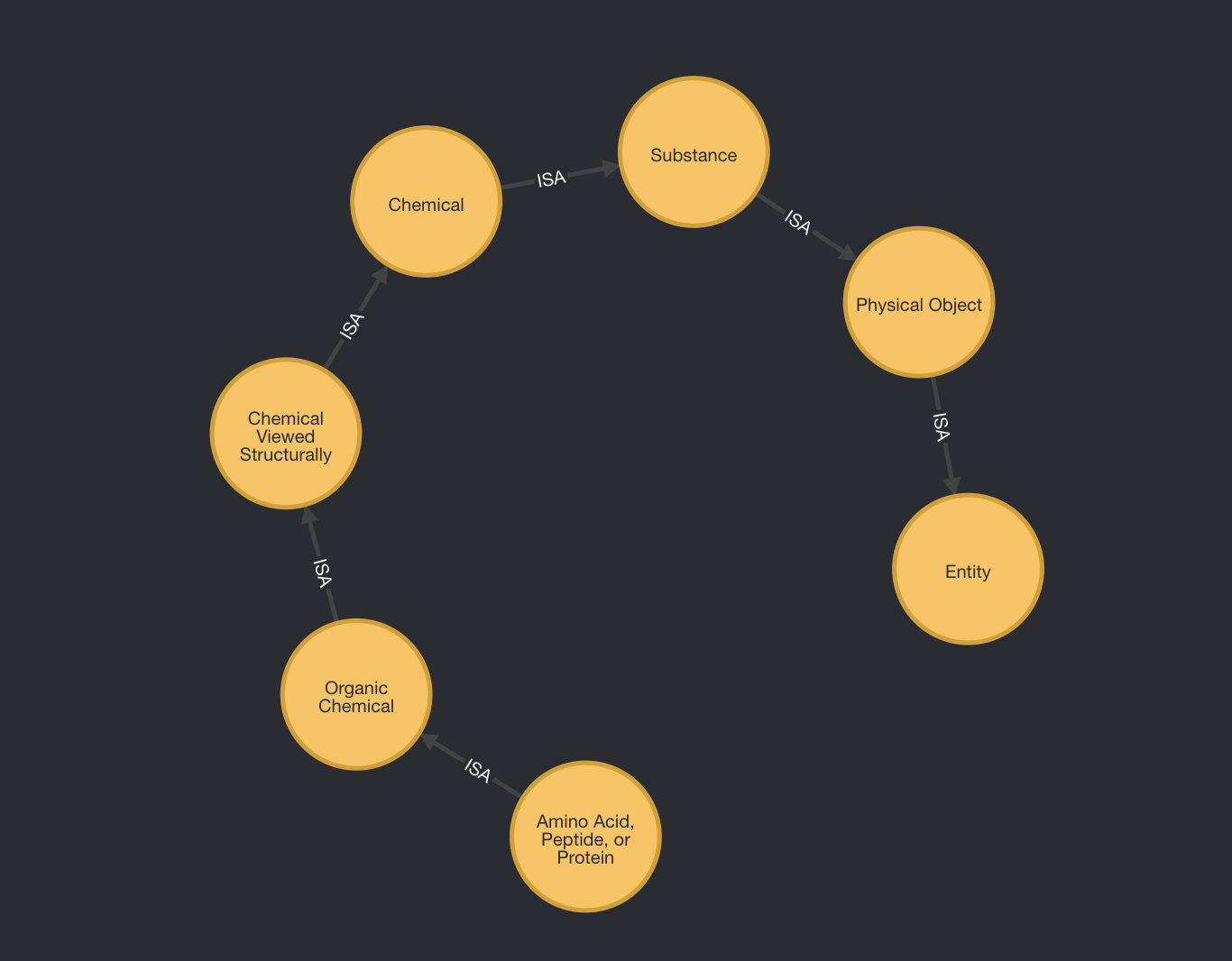
UMLS Semantic Network
Below is the exact semantic network provided by UMLS® Semantic Network Reference that has been modeled in this Neo4j LPG and briefly illustrated above.

(In Progress) - Neo4j Schema Mapped to RDF - The W3C Standard Model for Data Interchange on the Web
-
An on-going additional objective is to map this Neo4j UMLS Graph (label property graph) to the W3C standard model for data interchange on the web - RDF (Resource Description Framework).
- Here is a sample (very small sample) of a v0 W3C validated RDF representation of this Neo4j Graph of UMLS created in this repository.
- You can find the .rdf file here:
- The validation was performed via W3C RDF Validation
- Additional W3C valid RDF serializations exposing small portions of the graph can be found within the following directory ->
./output_data.
{kind=link}
Unified Medical Language System® (UMLS®) & Interoperability
In this repository, an exploration of a handful of the largest and/or industry relevant biomedical ontologies and terminologies (within the Unified Medical Language System® (UMLS®)).
Disclaimer - while this repository is open to anyone & has been created to share knowledge, educate & provide to open source community. In order to access the data covered, you must be a UMLS® license holder. Please visit How to License and Access the Unified Medical Language System® (UMLS®) Data to learn more.
The scope of material covered in this repository will pertain specifically to healthcare, biotechnology & pharmaceutics. Largely in regards to oncology. The terminologies and ontologies used in this repository available have been limited due to the enormous size of UMLS® (UMLS 2022AB containing >200+ terminologies constituting roughly a ~50-60GB MySQL database).
- Due to the shear size of UMLS the scope has been limited to appropriately 1/3 to 1/4 of entirety of UMLS to uplift inevitable resource constraints and enable local development.
- Despite the “limited” scope, the vocabularies chosen to be included all live at the forefront of bringing interoperability to healthcare (scope mostly being disease, genetics & pharmaceutics). The terminologies covered have been chosen based on their utility and the strong relations that exist among them.
- i.e. the terminologies SNOMEDCT_US, ICD9CM, ICD10CM, ICDO3, NCI, RXNORM, ATC all strongly relate to each other and depend on each other in ways in which they promote interoperability within healthcare.
- In addition, these terminologies contain among the richest concept hierarchies (parent/child/ancestor/descendant relationships) and semantic relationships (such as SNOMEDCT_US, NCI, GO, RXNORM, ATC).
- i.e. the terminologies SNOMEDCT_US, ICD9CM, ICD10CM, ICDO3, NCI, RXNORM, ATC all strongly relate to each other and depend on each other in ways in which they promote interoperability within healthcare.
- Despite the “limited” scope, the vocabularies chosen to be included all live at the forefront of bringing interoperability to healthcare (scope mostly being disease, genetics & pharmaceutics). The terminologies covered have been chosen based on their utility and the strong relations that exist among them.
What is the UMLS® & Why is it Important?
- “The UMLS® integrates and distributes key terminology, classification and coding standards, and associated resources to promote creation of more effective and interoperable biomedical information systems and services, including electronic health records.”
- The UMLS®, or Unified Medical Language System®, is a set of files and software that brings together many health and biomedical vocabularies and standards to enable interoperability between computer systems.
- UMLS® contains over 200+ industry standard biomedical vocabularies & ontologies. Check out contents (ontologies/vocabularies) contained within UMLS® via following link:
Terminologies within Scope of Repository (list subject to change)
- Anatomical Therapeutic Chemical Classification System:
- Abbreviation -> ATC
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> ATC
- Gene Ontology:
- Abbreviation -> GO
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> GO
- HUGO Gene Nomenclature Committee:
- Abbreviation -> HGNC
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> HGNC
- Human Phenotype Ontology:
- Abbreviation -> HPO
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> HPO
- International Classification of Diseases, Ninth Revision, Clinical Modification:
- Abbreviation -> ICD9CM
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> ICD9CM
- International Classification of Diseases, Tenth Revision, Clinical Modification:
- Abbreviation -> ICD10CM
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> ICD10CM
- ICD-10 Procedure Coding System:
- Abbreviation -> ICD10PCS
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> ICD10PCS
- LOINC:
- Abbreviation -> LNC
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> LNC
- MedDRA:
- Abbreviation -> MDR
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> MDR
- Medication Reference Terminology:
- Abbreviation -> MED-RT
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> MED-RT
- MeSH:
- Abbreviation -> MSH
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> MSH
- NCBI Taxonomy:
- Abbreviation -> NCBI
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> NCBI
- National Cancer Institute Thesaurus:
- Abbreviation -> NCI
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> NCI
- Physician Data Query:
- Abbreviation -> PDQ
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> PDQ
- RXNORM:
- Abbreviation -> RXNORM
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> RXNORM
- SNOMED CT, US Edition:
- Abbreviation -> SNOMEDCT_US
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> SNOMEDCT_US
- Source Terminology Names (UMLS):
- Abbreviation -> SRC
- NIH/UMLS Vocabulary Documentation:
- Abbreviation -> SRC
Python Environment Setup
We recommend using pyenv for easy switching between multiple versions of Python. This project requires Python 3.8 and above.
This project uses Poetry for dependency management. If you are not familiar with Poetry, please refer to their official documentation.
To set up the Python environment for this project, follow these steps:
-
Install pyenv and use it to install a version of Python 3.8 or above.
-
Create a virtual environment in the root directory of the project:
python -m venv .venv
source .venv/bin/activate
Install the dependencies by running:
poetry install
Getting started
- After running UMLS metamorphoSys (have source files) and your python environment has been setup. Navigate to relative directory
cd clinical_informatics_umls& run the python scriptcreate_sqlite_db.pyor run./sqlite/create_sqlite_db.sh(refer to code and modify as needed): - This will create a SQLite database containing all required tables, indexes and constraints needed to create the Neo4j Graph schema defined.
clinical_informatics_umls % poetry run python create_sqlite_db.py
creating umls_py.db
opening files
Creating tables
Inserting data into MRSTY table
Inserting data into MRCONSO table
Inserting data into MRREL table
Inserting data into MRHIER table
Inserting data into MRRANK table
Inserting data into SRDEF table
Inserting data into SRSTR table
Inserting data into SRSTRE1 table
Inserting data into SRSTRE2 table
Inserting data into MRSAB table
Creating indices
SQLite database created - umls_py.db
- If you want to use MySQL, Mariadb or PostgreSQL then refer to the load scripts available in
./databases/mysql/&./databases/postgres/ - Once you have loaded a RDBMS with your UMLS 2021AB subset, create a an directory called
import(at your home directory) - This directory needs to contain all the files that will be loaded into Neo4j. - This directory will be mounted outside the container to leverage using
neo4j-admin importtool. (Required for imports of >10 million nodes & takes only a minute or two). - Once you have created the directory (i.e.
$HOME/import) navigate back to the following directory./clinical_informatics_umls/clinical_informatics_umls.- Now we will execute another python script to generate csv files that constitute the node files and relationship files.
- The script will write out to all correctly formatted csv files for import but look over the docker run command along with your personal directory structure (i.e. import directory to be mounted).
- Upon the completion of the scripts execution we are ready to proceed with steps that follow
Neo4j Docker Setup & Data Import.
- Upon the completion of the scripts execution we are ready to proceed with steps that follow
- The script will write out to all correctly formatted csv files for import but look over the docker run command along with your personal directory structure (i.e. import directory to be mounted).
- Now we will execute another python script to generate csv files that constitute the node files and relationship files.
Neo4j Docker Setup & Data Import
Docker Image:
docker run --name=<INSERT NAME> \
-p7474:7474 -p7687:7687 \
--detach \
--volume=$HOME/neo4j/data:/data \
--volume=$HOME/import:/var/lib/neo4j/import \
--volume=$HOME/neo4j/plugins:/plugins \
--volume=$HOME/neo4j/backups:/backups \
--volume=$HOME/neo4j/data/rdf:/data/rdf \
--env=NEO4J_ACCEPT_LICENSE_AGREEMENT=yes \
--env=NEO4J_dbms_backup_enabled=true \
--env=NEO4J_apoc_export_file_enabled=true \
--env=NEO4J_apoc_import_file_enabled=true \
--env=NEO4J_apoc_import_file_use__neo4j__config=true \
--env=NEO4J_apoc_export_file_use__neo4j__config=true \
--env=NEO4JLABS_PLUGINS='["apoc", "graph-data-science", "n10s"]' \
--env=NEO4J_dbms_memory_pagecache_size=4G \
--env NEO4J_dbms_memory_heap_initial__size=8G \
--env NEO4J_dbms_memory_heap_max__size=8G \
--env=NEO4J__dbms_jvm_additional=-Dunsupported.dbms.udc.source=debian \
--env=NEO4J_dbms_memory_heap_initial_tx_state_memory__allocation=ON_HEAP \
--env=NEO4J_AUTH=neo4j/<INSERT PWD> \
--env=NEO4J_dbms_unmanaged__extension__classes=n10s.endpoint=/rdf \
neo4j:4.4.6-enterprise
Import Data Into Neo4j Graph
-
Importing the .csv files will require use of Neo4j’s
neo4j-admin importtool- Required for imports > 10 million nodes/edges
-
Execute the following commands within your terminal:
-
docker exec -it <CONTAINER ID> /bin/bash-
Your terminal should appear as follows:
-
root@<CONTAINER ID>:/var/lib/neo4j# -
The character string following
root@should be the DockerCONTAINER ID. -
This is where we can invoke
neo4j-admin import.
-
-
-
-
Ensure you have correctly mounted volumes appropriately & the
importdirectory is not not located within the directoryneo4j. - While inside docker containers command-line, execute the following prior to import:
rm -rf data/databases/rm -rf data/transactions/- Please be aware that is best to execute above two commands twice prior to running
neo4j-admin import
- NOTE: This is a required step when using
neo4j-admin import.- By invoking this command to import data, the database for your data must not already exist as well.
- Now the database can be created & imported into. Execute the following:
./bin/neo4j-admin import \
--database=neo4j \
--nodes='import/styNodes.csv' \
--nodes='import/cuiNodes.csv' \
--nodes='import/auiNodes.csv' \
--nodes='import/codeNodes.csv' \
--relationships='import/has_sty_rel.csv' \
--relationships='import/has_aui_rel.csv' \
--relationships='import/has_cui_rel.csv' \
--relationships='import/tui_tui_rel.csv' \
--relationships='import/cui_cui_rel.csv' \
--relationships='import/parent_child_rel.csv' \
--relationships='import/cui_code_rel.csv' \
--skip-bad-relationships=true \
--skip-duplicate-nodes=true
Here are a few snippets of what the above commands should look like (including both inputs & outputs):
% docker exec -it <CONTAINER ID> /bin/bash
/var/lib/neo4j# rm -rf data/databases/
/var/lib/neo4j# rm -rf data/transactions/
/var/lib/neo4j# ./bin/neo4j-admin import \
--database=neo4j \
--nodes='import/styNodes.csv' \
--nodes='import/cuiNodes.csv' \
--nodes='import/auiNodes.csv' \
--nodes='import/codeNodes.csv' \
--relationships='import/has_sty_rel.csv' \
--relationships='import/has_aui_rel.csv' \
--relationships='import/has_cui_rel.csv' \
--relationships='import/tui_tui_rel.csv' \
--relationships='import/cui_cui_rel.csv' \
--relationships='import/parent_child_rel.csv' \
--relationships='import/cui_code_rel.csv' \
--skip-bad-relationships=true \
--skip-duplicate-nodes=true
Output:
Importing the contents of these files into /var/lib/neo4j/data/databases/neo4j:
Nodes:
/var/lib/neo4j/import/styNodes.csv
/var/lib/neo4j/import/cuiNodes.csv
/var/lib/neo4j/import/auiNodes.csv
/var/lib/neo4j/import/codeNodes.csv
Relationships:
/var/lib/neo4j/import/has_sty_rel.csv
/var/lib/neo4j/import/has_aui_rel.csv
/var/lib/neo4j/import/has_cui_rel.csv
/var/lib/neo4j/import/tui_tui_rel.csv
/var/lib/neo4j/import/cui_cui_rel.csv
/var/lib/neo4j/import/parent_child_rel.csv
/var/lib/neo4j/import/cui_code_rel.csv
...
Estimated number of nodes: 17.01 M
Estimated number of node properties: 66.68 M
Estimated number of relationships: 49.20 M
Estimated number of relationship properties: 18.33 M
Estimated disk space usage: 4.408GiB
Estimated required memory usage: 880.4MiB
(1/4) Nodes import
...
(2/4) Relationship import
...
(3/4) Relationship linking
...
(4/4) Post processing
...
Imported:
16838348 nodes
42934606 relationships
79579572 properties
Exit docker command-line via:
exit
Need to restart the container:
-
docker restart <CONTAINER ID> -
Once container has been restarted (s/p successful import), go ahead and Navigate to Neo4j Browser within a browser & login using the credentials set via the environmental variable
env=NEO4J_AUTH=neo4j/<password>.- user:
neo4j(default isneo4j-> set in--env=NEO4J_AUTH=neo4j/<password>) - pass:
<password>-> set prior via--env=NEO4J_AUTH=neo4j/<password>)
- user:
Querying the UMLS as a Neo4j Graph
More to come…